ReTabAD: A Benchmark for Restoring Semantic Context in Tabular Anomaly Detection
🎯 Overview
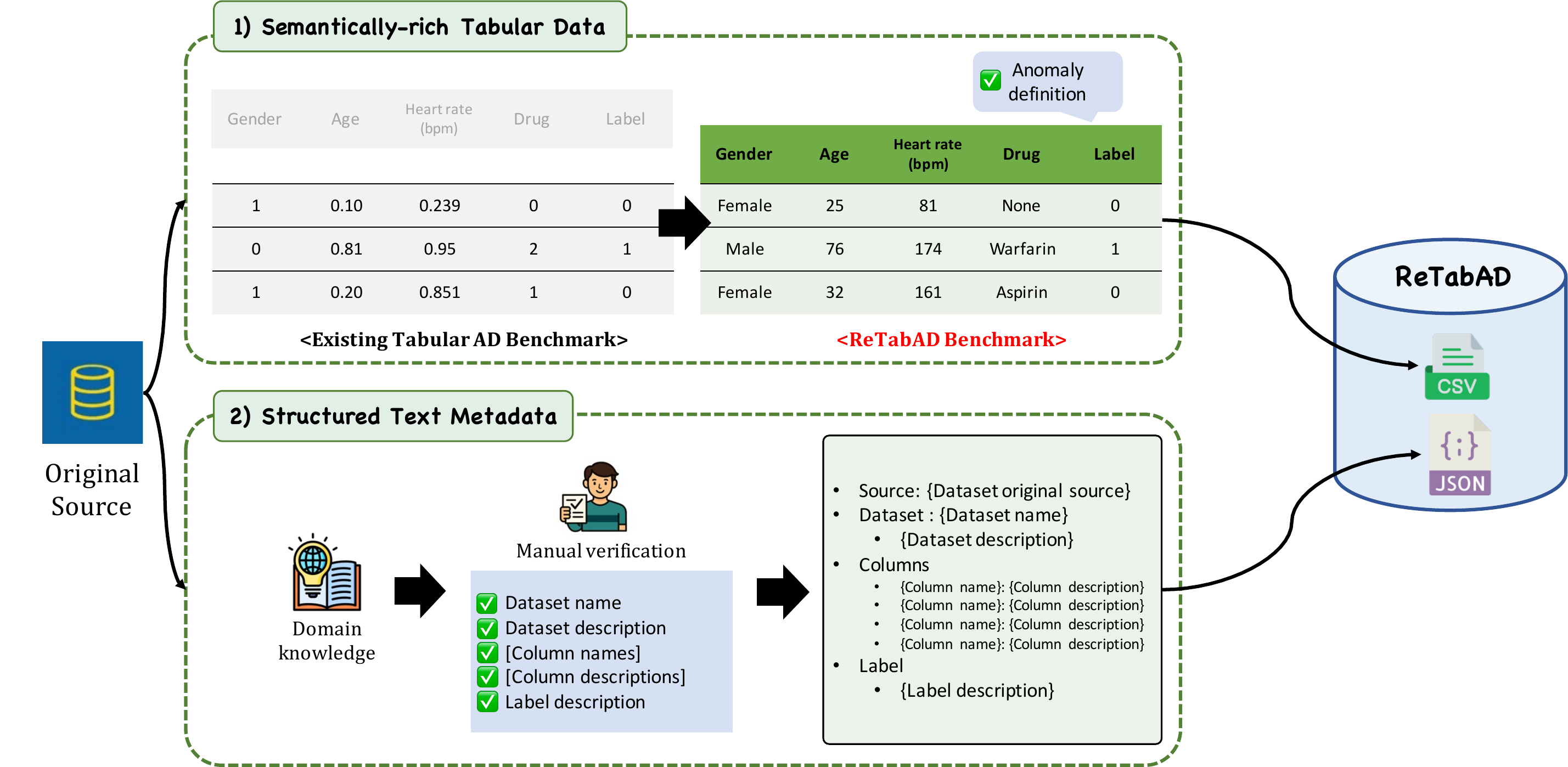
In tabular anomaly detection (AD), textual semantics often carry critical signals, as the definition of an anomaly is closely tied to domain-specific context. However, existing benchmarks provide only raw data points without semantic context, overlooking rich textual metadata such as feature descriptions and domain knowledge that experts rely on in practice. This limitation restricts research flexibility and prevents models from fully leveraging domain knowledge for detection. ReTabAD addresses this gap by Restoring textual semantics to enable context-aware Tabular AD research. We provide (1) 20 carefully curated tabular datasets enriched with structured textual metadata, together with implementations of state-of-the-art AD algorithms—including classical, deep learning, and LLM-based approaches—and (2) a zero-shot LLM framework that leverages semantic context without task-specific training, establishing a strong baseline for future research. Furthermore, this work provides insights into the role and utility of textual metadata in AD through experiments and analysis. Results show that semantic context improves detection performance and enhances interpretability by supporting domain-aware reasoning. These findings establish ReTabAD as a benchmark for systematic exploration of context-aware AD.
✨ Key Features
📚 Semantically-Rich Datasets
Tabular data paired with comprehensive JSON text metadata containing column descriptions, logical types, and characterizations of normal data.
💡 Support SOTA Algorithms
Unified pipeline enabling fair comparisons across traditional ML, deep learning, and modern LLM approaches.
🚀 LLM Potential
Demonstrates substantial performance improvements when models can leverage semantic information.
🔬 Why ReTabAD?
Traditional tabular AD benchmarks exhibit a fundamental disconnect from industrial practice:
- ❌ Lost Semantics: Textual features converted to opaque encodings
- ❌ Missing Context: Descriptive metadata discarded
- ❌ Rigid Preprocessing: Limits research flexibility
- ❌ No Domain Knowledge: Prevents models from using expert insights
ReTabAD solves these problems by restoring semantic context and enabling context-aware AD research.
📊 Benchmark Statistics
ReTabAD includes 20 diverse datasets spanning multiple domains:
| Dataset Name | Datapoints | Columns | Normal Count | Anomaly Count | Anomaly Ratio (%) |
|---|---|---|---|---|---|
| automobile | 159 | 25 | 117 | 42 | 26.42 |
| backdoor | 29,223 | 42 | 29,113 | 110 | 0.38 |
| campaign | 7,842 | 16 | 6,056 | 1,786 | 22.77 |
| cardiotocography | 2,126 | 21 | 1,655 | 471 | 22.15 |
| census | 50,000 | 41 | 47,121 | 2,879 | 5.76 |
| churn | 7,032 | 19 | 5,163 | 1,869 | 26.58 |
| cirrhosis | 247 | 17 | 165 | 82 | 33.20 |
| covertype | 50,000 | 12 | 49,520 | 480 | 0.96 |
| credit | 30,000 | 23 | 23,364 | 6,636 | 22.12 |
| equip | 7,672 | 6 | 6,905 | 767 | 10.00 |
| gallstone | 241 | 38 | 161 | 80 | 33.20 |
| glass | 214 | 9 | 163 | 51 | 23.83 |
| glioma | 730 | 23 | 487 | 243 | 33.29 |
| quasar | 50,000 | 8 | 40,520 | 9,480 | 18.96 |
| seismic | 2,584 | 18 | 2,414 | 170 | 6.58 |
| stroke | 4,909 | 10 | 4,700 | 209 | 4.26 |
| vertebral | 310 | 6 | 210 | 100 | 32.26 |
| wbc | 535 | 30 | 357 | 178 | 33.27 |
| wine | 178 | 13 | 130 | 48 | 26.97 |
| yeast | 1,484 | 8 | 1,389 | 95 | 6.40 |
🚀 Quick Start
# Clone the repository
git clone https://github.com/yoonsanghyu/ReTabAD.git
cd ReTabAD
# Build Docker image
docker build -t retabad:1.0.0 .
# Run experiment
python run_default.py --data_name wine --model_name OCSVM --cfg_file configs/default/pyod/OCSVM.yaml
See Usage for detailed instructions.
📰 News
- 2025-09-30: Initial release of ReTabAD benchmark
- 2025-09-30: 20 datasets with semantic metadata published
- 2025-09-30: GitHub repository and documentation launched